Se você desenvolve APIs em Delphi, provavelmente já ouviu o mito de que o Delphi não serve para backend web de alto desempenho na nuvem ou de que ele consome muita memória. Hoje, vamos desmistificar essa falácia por completo.
Por alguns dias estive estudando o httpsys e epoll, o primeiro para windows e o segundo para linux, visando melhorar o provedor epoll do DEXTe acrescentar ao HORSE provedores para httpsys e epoll, o ponto de partida dessa empreitada foi tentar entender melhor como tudo acontece nos bastidores e como otimizar ao maximo um servidor feito em delphi, para isso utilizei estes dois projetos dos quais tenho participado bastante.
Neste artigo, vamos analisar a fundo o desenvolvimento do Horse Epoll, um provedor nativo assíncrono de transporte HTTP construído para Linux, e entender como técnicas avançadas de programação de baixo nível elevaram o Delphi a patamares de performance brutais, batendo 29.710 requisições por segundo em contêineres Docker.
O Calcanhar de Aquiles: Por que o modelo tradicional do Indy não escala no Linux?
Por padrão, a maioria dos servidores Horse e da própria Embarcadero utiliza o Indy como motor de transporte. O Indy foi construído sob um modelo síncrono e bloqueante conhecido como Thread-per-Connection.
Nesse modelo, o fluxo funciona assim:
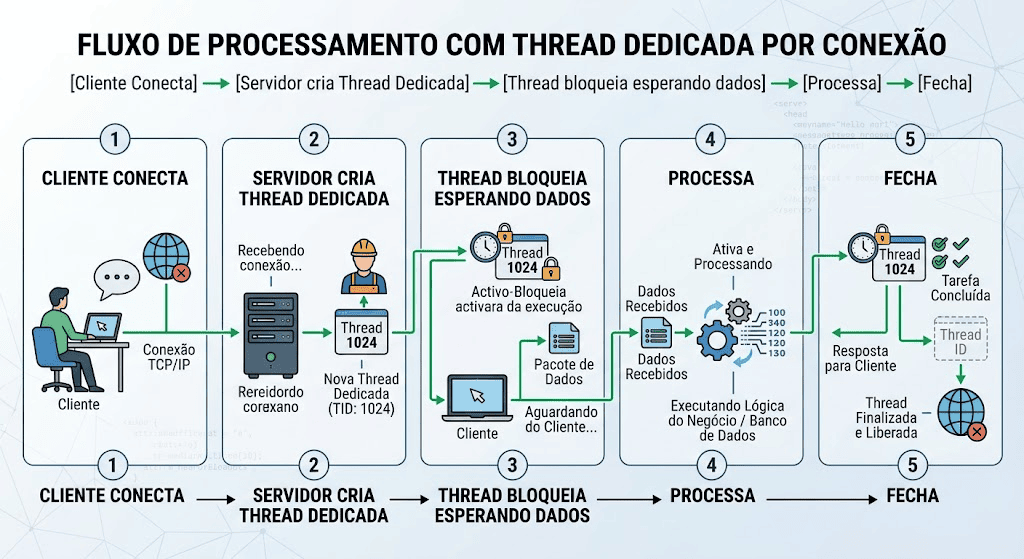
O que acontece quando escalamos para 1.000 clientes simultâneos?
- Chaveamento de Contexto Preemptivo (CPU Thrashing): O Linux precisa alternar o tempo de processamento físico da CPU entre 1.000 threads. Salvar o estado dos registradores da thread
Ana memória e carregar a threadBconsome tanta CPU que o servidor perde mais tempo trocando de tarefa do que de fato processando requisições HTTP. - Esgotamento da Fila de Sockets (TCP Backlog): Como a CPU está ocupada gerenciando threads, o servidor demora para executar a chamada
accept()nas conexões pendentes. A fila de backlog TCP do kernel lota, e o sistema operacional começa a descartar conexões novas, gerando erros de timeout no lado do cliente. - Consumo de Memória Elevado: Cada thread criada aloca, por padrão, uma pilha (stack size) de cerca de 1MB a 2MB na RAM. Apenas para manter 1.000 conexões ativas abertas e sem tráfego, o servidor consome de 1GB a 2GB de RAM à toa.
A Solução: Como o Horse Epoll funciona por baixo do capô?
Para quebrar essa parede de escalabilidade, o provedor Epoll foi construído do zero usando a API nativa de multiplexação do kernel do Linux: o epoll.
Em vez de criar uma thread por conexão, o Epoll opera no modelo Event-Loop (reativo):

O servidor mantém um pool pequeno e fixo de threads (normalmente uma thread por núcleo físico da CPU). Uma única chamada de sistema (epoll_wait) pergunta ao kernel do Linux quais sockets possuem dados prontos para leitura ou escrita. Se um socket estiver inativo, ele não consome CPU e nem aloca threads extras no sistema operacional.
As 5 Otimizações de Ouro Explicadas no Código
Apenas mudar para o Epoll não era suficiente para extrair toda a performance do compilador Delphi. Aplicamos 5 otimizações cruciais diretamente no código fonte:
1. Thread-Local Buffer Pool (threadvar)
A alocação e liberação constante de memória de buffers HTTP em ambientes multi-thread cria uma barreira no gerenciador de memória do Delphi (FastMM), gerando contenção por travas globais (Lock Contention). A CPU passa a competir para ver qual thread ganha o direito de alocar memória na heap.
Como resolvemos: Usamos variáveis locais às threads de trabalho (threadvar) para criar pools de memória isolados por thread:
threadvar LBufferPool: THorseBufferPool; // Isolado de concorrência global
Cada worker thread aloca buffers do seu pool local pré-alocado. Como não há concorrência por recursos entre as threads, as travas de memória caem para zero, e o uso de CPU escala linearmente em processadores multi-core.
2. Parsing HTTP Zero-Allocation (Com Ponteiros)
Converter arrays de bytes recebidos do socket em strings (string no Delphi) para analisar o método (GET), o caminho (/ping) e cabeçalhos HTTP aloca memória heap intensamente e gera um overhead gigante de contadores de referência de strings.
Como resolvemos: Implementamos um parser com alocação zero de memória. Varremos o buffer bruto utilizando ponteiros (PByte) e offsets para mapear os cabeçalhos diretamente da memória compartilhada:
var
LStart, LEnd: PByte;
LMethodLength: Integer;
begin
LStart := FBufferPtr; // Procura pelo espaço que delimita o método HTTP ("GET ")
while (LStart < FBufferEnd) and (LStart^ <> 32) do
Inc(LStart);
LMethodLength := LStart - FBufferPtr;
// Apenas lemos os offsets de bytes, sem instanciar strings na heap!
end;
As strings do Delphi só são instanciadas na regra de negócio se o usuário explicitamente chamá-las.
3. Escritas Vetorizadas com writev
Em uma resposta HTTP padrão, o servidor envia os cabeçalhos (ex: HTTP/1.1 200 OK, Content-Length) e depois o corpo da resposta. Fazer dois ou mais comandos send() seguidos força a CPU a fazer múltiplas chamadas de sistema, o que é lento devido às trocas de contexto entre o espaço do usuário e o espaço do kernel.
Como resolvemos: Usamos a chamada nativa do Linux writev, que permite passar um array de buffers e escrevê-los de uma única vez:
type iovec = record
iov_base: Pointer;
iov_len: Cardinal;
end;
var LBuffers: array[0..1] of iovec;
begin
LBuffers[0].iov_base := FHeaderBuffer;
LBuffers[0].iov_len := FHeaderLen;
LBuffers[1].iov_base := FBodyBuffer;
LBuffers[1].iov_len := FBodyLen;
// Envia cabeçalhos + corpo em uma única chamada atômica do kernel!
writev(FSocketFD, @LBuffers[0], 2);
end;
4. Zero-Copy I/O de Arquivos com sendfile
Enviar arquivos grandes em APIs (como PDFs ou imagens) costuma exigir carregar o arquivo em memória no Delphi (TFileStream) e depois passá-lo para o buffer de socket. Isso causa dupla cópia de memória e desperdiça CPU e RAM.
Como resolvemos: Usamos a chamada de sistema sendfile do Linux, que faz a transferência diretamente no espaço de kernel (do cache do disco para o buffer da placa de rede):
socketsendfile(FSocketFD, FFileDescriptor, nil, LFileSize);
5. Auto-tuning do Linux via Código (RLIMIT_NOFILE)
O Linux possui restrições internas para evitar que um processo ocupe mais de 1.024 descritores de arquivos (sockets abertos simultâneos).
Como resolvemos: Inserimos uma autoelevação automatizada no startup do provedor utilizando a biblioteca nativa libc:
var
LRLimit: rlimit;
begin
LRLimit.rlim_cur := 65535;
LRLimit.rlim_max := 65535;
setrlimit(RLIMIT_NOFILE, LRLimit);
end;
Isso faz com que o servidor se reconfigure sozinho no startup para aguentar milhares de conexões, eliminando configurações manuais complexas em produção.
Cenário e Metodologia de Benchmark
Para atestar o impacto real dessas otimizações, compilamos ambos os servidores (Horse Indy e Horse Epoll) em Linux 64-bit e os rodamos sob contêineres Docker independentes conectados em uma rede dedicada do tipo Bridge.
Usamos o utilitário Apache Benchmark (ab) rodando em outro contêiner isolado para gerar uma carga severa de estresse:
- Requisições Totais (
-n): 20.000 - Conexões Simultâneas (
-c): 1.000 - Dois Cenários de Conexão: Com e Sem Keep-Alive (Sockets persistentes).
Os Resultados Reais do Benchmark
Os resultados foram avassaladores e expuseram claramente a diferença arquitetural dos dois provedores, mas vale fazer um parêntese técnico importante sobre este teste de 1.000 conexões simultâneas: este é um cenário de estresse sintético extremo. No mundo real, a menos que você esteja rodando uma API pública de escala massiva ou enfrentando picos como uma Black Friday, a concorrência instantânea (requisições batendo no exato mesmo milissegundo) raramente atinge essa marca, mesmo em sistemas com milhares de usuários ativos.
Como o Indy trabalha no modelo tradicional de alocar uma thread por conexão, esse volume de conexões simultâneas causa um overhead severo de troca de contexto de CPU e esgotamento de recursos do sistema operacional. Para a maioria das aplicações do dia a dia, o Indy continuará atendendo com total estabilidade. O objetivo de levarmos os servidores ao limite foi puramente didático: mostrar onde fica o ponto de ruptura do modelo síncrono e como a arquitetura não-bloqueante do Epoll consegue gerenciar essa carga extrema com consumo mínimo de recursos e zero falhas.
Tabela Geral Comparativa
| Provedor / Cenário | Status do Teste | Vazão (RPS) | Latência Média (ms) | Latência 99% (ms) |
|---|---|---|---|---|
| Horse Indy (Sem Keep-Alive) | Falhou | 0.0 | N/A | N/A |
| Horse Indy (Com Keep-Alive) | Falhou | 0.0 | N/A | N/A |
| Horse Epoll (Sem Keep-Alive) | Sucesso | 11.075,96 | 90,28 ms | 117,00 ms |
| Horse Epoll (Com Keep-Alive) | Sucesso | 29.710,66 | 33,65 ms | 57,00 ms |
Gráficos de Desempenho
Vazão de Requisições (RPS)

Latência Média por Requisição (ms)

Distribuição Detalhada de Latência (Epoll)
A distribuição de tempo do Epoll mostra uma consistência incrível sob concorrência de 1.000 conexões:
- 50% das requisições (Mediana): 102 ms (Sem Keep-Alive) | 33 ms (Com Keep-Alive)
- 99% das requisições (Percentil): 117 ms (Sem Keep-Alive) | 57 ms (Com Keep-Alive)
- Tempo Máximo (Pior Caso): 206 ms (Sem Keep-Alive) | 206 ms (Com Keep-Alive)
Como habilitar o Epoll no seu servidor hoje?
Se você já desenvolve com Horse, habilitar o suporte assíncrono ao Epoll nativo de Linux é extremamente simples:
- Instale o framework via Boss: boss install horse
- Adicione nas Conditional Defines do seu projeto Delphi o define: HORSE_PROVIDER_EPOLL
- Escreva o seu servidor normalmente e compile-o para Linux:
program MyServer;
{$APPTYPE CONSOLE}
uses Horse;
begin
THorse.Get('/ping',
procedure(Req: THorseRequest; Res: THorseResponse)
begin
Res.Send('pong');
end);
THorse.Listen(9095);
end.
O Horse se encarrega de mapear internamente as chamadas de socket do Delphi para a API assíncrona do Epoll quando o binário é compilado e executado no Linux!
Conclusão
O desenvolvimento e os benchmarks do Horse Epoll provam de uma vez por todas que o Delphi é uma tecnologia extremamente viável, robusta e rápida para o desenvolvimento de APIs modernas na nuvem.
Ao trocar o modelo obsoleto de Thread-per-Connection pelo event-loop do Epoll do Linux e aplicar técnicas eficientes como Zero-Allocation Parsing e Thread-Local Pools, o Delphi não apenas atendeu à carga de concorrência que derrubou o Indy, mas o fez com uma vazão impressionante de quase 30.000 requisições por segundo.
Descubra mais sobre Régys Borges da Silveira
Assine para receber nossas notícias mais recentes por e-mail.



Dê-nos sua opinião, seu comentário ajuda o site a crescer e melhorar a qualidade dos artigos.