O uso de Inteligência Artificial no desenvolvimento de software tornou-se um requisito para manter a eficiência. No entanto, a dependência de APIs externas traz desafios como latência, custos variáveis e, principalmente, preocupações com a privacidade de códigos proprietários.
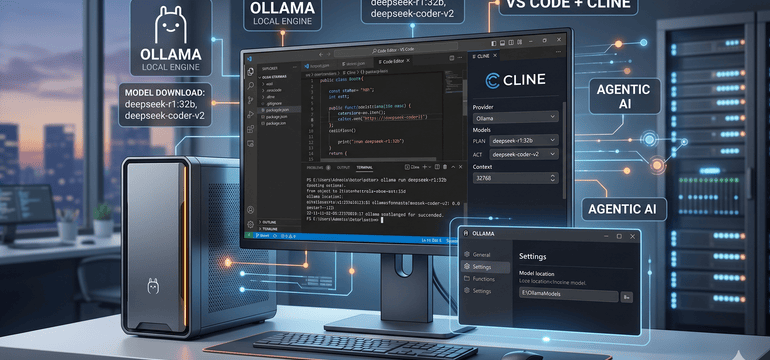
Neste artigo, detalho como configurar o Ollama, o motor principal para execução de LLMs localmente, os modelos deepseek, e como integrá-lo ao seu fluxo de trabalho no VS Code utilizando o Cline para garantir um ambiente seguro e de alta performance.
1. O Motor: Ollama
O Ollama consolidou-se como o padrão open-source para rodar modelos de linguagem (LLMs) localmente. Ele simplifica a gestão de pesos e bibliotecas, permitindo subir modelos robustos com comandos simples.
Especificações de Hardware Recomendadas
Para uma experiência fluida com modelos de 30B ou superiores:
- RAM: 32GB a 64GB, essencial para carregar modelos de grande porte na memória.
- Armazenamento: SSD NVMe para carregamento rápido dos pesos.
- GPU: Embora o Ollama utilize núcleos CUDA da NVIDIA para performance instantânea, ele opera com eficiência via CPU e RAM compartilhada em máquinas modernas.
2. Instalação e Gestão de Dados
Passo a Passo
- Download: Acesse o site oficial do Ollama e baixe a versão para seu sistema operacional.
- Instalação: Siga as instruções do assistente padrão (next, next, finish).
- Verificação: No terminal, execute
ollama --version.
Gestão de Armazenamento e Performance (Multi-HD)
Modelos mais robustos podem ocupar dezenas de gigabytes. Para evitar sobrecarregar o disco principal (C:), você pode configurar o local de armazenamento dos modelos diretamente na interface do Ollama:
- Abra as configurações (Settings) do aplicativo Ollama, o icone fica no systray ao lado do relógio do windos.
- Localize a opção de localização do modelo (Model location).
- Clique em Browse e selecione a pasta no seu HD ou SSD secundário.
- Aproveite para ajustar o Context length para 32k ou 64k, aproveitando a disponibilidade de memória RAM para analisar múltiplos arquivos simultaneamente.
3. Instalação dos Modelos (Download)
Após instalar o motor do Ollama, é necessário baixar os modelos (LLMs) que serão utilizados. Este processo é feito via terminal (PowerShell ou Prompt de Comando).
Modelos Recomendados para Desenvolvimento
Para o fluxo de trabalho atual, utilizaremos dois modelos principais:
- Modelo de Raciocínio (Cérebro): Execute o comando:
ollama run deepseek-r1:32bEste modelo é focado em lógica complexa e planejamento de arquitetura. - Modelo de Escrita de Código (Executor): Execute o comando:
ollama run deepseek-coder-v2Este modelo é otimizado para a escrita rápida de código e possui um vasto conhecimento de sintaxes de programação.
Você pode listar todos os modelos baixados em sua máquina a qualquer momento com o comando: ollama list.
4. Integração de com Cline
O Cline é uma extensão para o VS Code que oferece capacidades agentivas completas rodando sobre o seu hardware. Ele permite que a IA tenha autonomia para ler arquivos, planejar mudanças e executar código.
Para instalar no VSCode, vá em extensions (Control+Shift+X) e procure por Cline, clique em instalar, após instalação um ícone do cline será mostrado na barra esquerda do VSCode.
Configuração do Provedor
- No painel do Cline, acesse as configurações (ícone de engrenagem no canto direito da tela do Cline).
- Em API Provider, selecione Ollama.
- Configure a Base URL para
http://localhost:11434. - Ative a opção “Use different models for Plan and Act modes”.
- No Plan Mode (O Cérebro), selecione o
deepseek-r1:32bpara arquitetura e lógica. - No Act Mode (O Executor), selecione o
deepseek-coder-v2para escrita de código rápida. - Configure o Model Context Window para 32768.
5. Workflow e Governança
Trabalhar localmente permite que você forneça contextos sensíveis, como o README.md do seu projeto e diretrizes de Clean Code, sem riscos de segurança. Isso garante que o código gerado pelo Cline siga rigorosamente os padrões de arquitetura definidos, eliminando códigos genéricos.
Se o processamento de modelos muito pesados causar lentidão em tarefas simultâneas, o equilíbrio ideal para máquinas com 64GB de RAM é utilizar versões de 32B, que oferecem excelente precisão sem comprometer a fluidez do sistema.
Referências
OLLAMA. Ollama Documentation. Disponível em: https://ollama.com/library. Acesso em: 18 abr. 2026.
CLINE. Cline: Autonomous AI Agent for VS Code. Disponível em: https://github.com/cline/cline. Acesso em: 18 abr. 2026.
Descubra mais sobre Régys Borges da Silveira
Assine para receber nossas notícias mais recentes por e-mail.
Dê-nos sua opinião, seu comentário ajuda o site a crescer e melhorar a qualidade dos artigos.